I’ve been working with Google’s MediaPipe which is a augmented reality (AR) library that can be used on low power devices (such as a phone). Basically MediaPipe is a collection of pre-trained AI that lets a developer do some interesting things. You can use it for single images or video sources such as a webcam.
Data such as face detection, hand detection, and pose detection come in the form of a tuple. That means that a detection result at any given index will always represent the same thing, such as a pose landmark detection reading nose positional data into index 0.
Today I’d like to share a technique I’ve used that might be useful to others. I’m using an enum to translate the numeric index value to something more human readable. The technique is great for creating a legible map between MediaPipe’s pose and Unity’s HumanBodyBones.
Pose Landmarker
The pose landmark detection feature is honestly amazing. As it says on the tin, a developer is able to obtain a pose from an input image. That pose can later be used for interesting things like manipulating a virtual avatar.
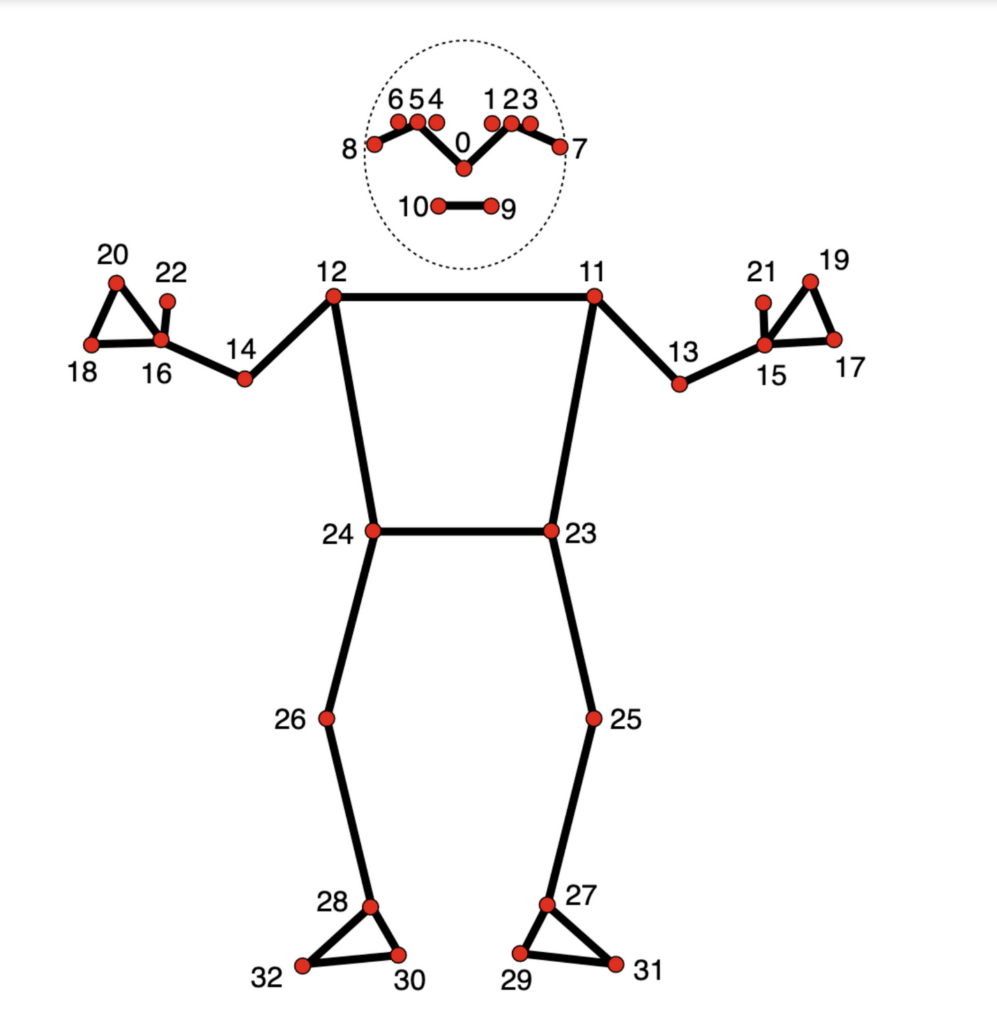
Source: https://ai.google.dev/edge/mediapipe/solutions/vision/pose_landmarker
Here’s the enum I use:
public enum PoseLandmark
{
Nose = 0,
LeftEyeInner = 1,
LeftEye = 2,
LeftEyeOuter = 3,
RightEyeInner = 4,
RightEye = 5,
RightEyeOuter = 6,
LeftEar = 7,
RightEar = 8,
MouthLeft = 9,
MouthRight = 10,
LeftShoulder = 11,
RightShoulder = 12,
LeftElbow = 13,
RightElbow = 14,
LeftWrist = 15,
RightWrist = 16,
LeftPinky = 17,
RightPinky = 18,
LeftIndex = 19,
RightIndex = 20,
LeftThumb = 21,
RightThumb = 22,
LeftHip = 23,
RightHip = 24,
LeftKnee = 25,
RightKnee = 26,
LeftAnkle = 27,
RightAnkle = 28,
LeftHeel = 29,
RightHeel = 30,
LeftFootIndex = 31,
RightFootIndex = 32
}
// Usage
private void OnPoseLandmarkerResult(PoseLandmarkerResult result)
{
var normalizedLandmarks = result.poseLandmarks[0].landmarks;
for (var i = 0; i < normalizedLandmarks.Count && i < _spheres.Count; i++)
{
var landmarkData = normalizedLandmarks[i];
var type = (PoseLandmark)i;
}
}
Hand Landmarker
Hand landmark detection is similar to pose detection; you get positional data for detected hands in an image.
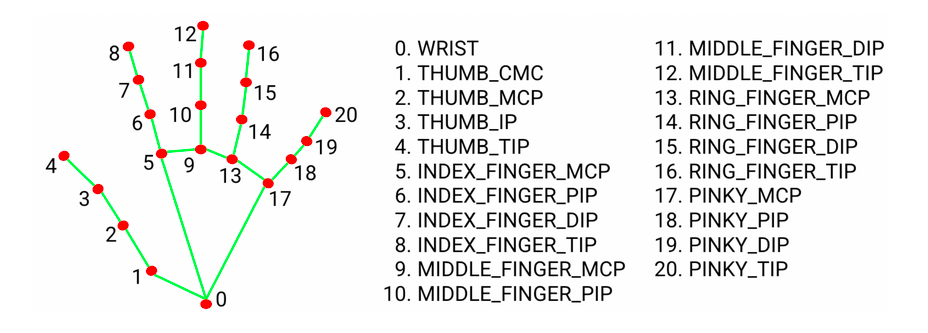
Source: https://ai.google.dev/edge/mediapipe/solutions/vision/hand_landmarker
And once again, the enum I use:
public enum HandLandmark
{
Wrist = 0,
ThumbCMC = 1,
ThumbMCP = 2,
ThumbIP = 3,
ThumbTip = 4,
IndexFingerMCP = 5,
IndexFingerPIP = 6,
IndexFingerDIP = 7,
IndexFingerTip = 8,
MiddleFingerMCP = 9,
MiddleFingerPIP = 10,
MiddleFingerDIP = 11,
MiddleFingerTip = 12,
RingFingerMCP = 13,
RingFingerPIP = 14,
RingFingerDIP = 15,
RingFingerTip = 16,
PinkyMCP = 17,
PinkyPIP = 18,
PinkyDIP = 19,
PinkyTip = 20
}
// Alternative, if you don't like abbreviations
public enum HandLandmark
{
Wrist = 0,
ThumbCarpometacarpalJoint = 1,
ThumbMetacarpophalangealJoint = 2,
ThumbInterphalangealJoint = 3,
ThumbTip = 4,
IndexFingerMetacarpophalangealJoint = 5,
IndexFingerProximalInterphalangealJoint = 6,
IndexFingerDistalInterphalangealJoint = 7,
IndexFingerTip = 8,
MiddleFingerMetacarpophalangealJoint = 9,
MiddleFingerProximalInterphalangealJoint = 10,
MiddleFingerDistalInterphalangealJoint = 11,
MiddleFingerTip = 12,
RingFingerMetacarpophalangealJoint = 13,
RingFingerProximalInterphalangealJoint = 14,
RingFingerDistalInterphalangealJoint = 15,
RingFingerTip = 16,
PinkyFingerMetacarpophalangealJoint = 17,
PinkyFingerProximalInterphalangealJoint = 18,
PinkyFingerDistalInterphalangealJoint = 19,
PinkyFingerTip = 20
}
// Usage
public void OnHandLandmarkerResult(HandLandmarkerResult result)
{
var normalizedLandmarks = result.handLandmarks[0].landmarks;
for (int i = 0; i < normalizedLandmarks.Count; i++)
{
var landmarkData = normalizedLandmarks[i];
var type = (HandLandmark)i;
}
}
Conclusion
The intention with this technique is to avoid having to look up what landmark the particular detection result maps to during development. Hope this technique is found to be useful for some folks out there.